Hi Sergio, I try to answer to your many questions on the subject… and sorry if I could not answer before as I was on leave in the last few days.
Thank you for your elaborate and kind response  I am sorry if it read as pushy, it was not my intention. I just wanted to make sure to bring your attention to it in case it was missed.
I am sorry if it read as pushy, it was not my intention. I just wanted to make sure to bring your attention to it in case it was missed.
The documentation you have found is all what is available at the moment.
I will try to find time to contribute to that page after I understand things better.
Regarding the G4AllocatorList , yes, we can add an accessor to allow browsing the list.
Great that it can be accessed. I suppose that this applies then to pDynamicParticleAllocator(), ie can its declaration be moved to the header file?
Let me premise that in general and with MT applications in particular, it is important to tune (a) the number of events per run to simulate and (b) the total number of threads to use, based on the resources of the system in use and the complexity of the simulation.
Our current strategy is more about restricting the size of the problem and throwing more money at it and getting more memory  But yes, you are right. About the number of events, that is not something I had thought of, so that is something to test, thank you.
But yes, you are right. About the number of events, that is not something I had thought of, so that is something to test, thank you.
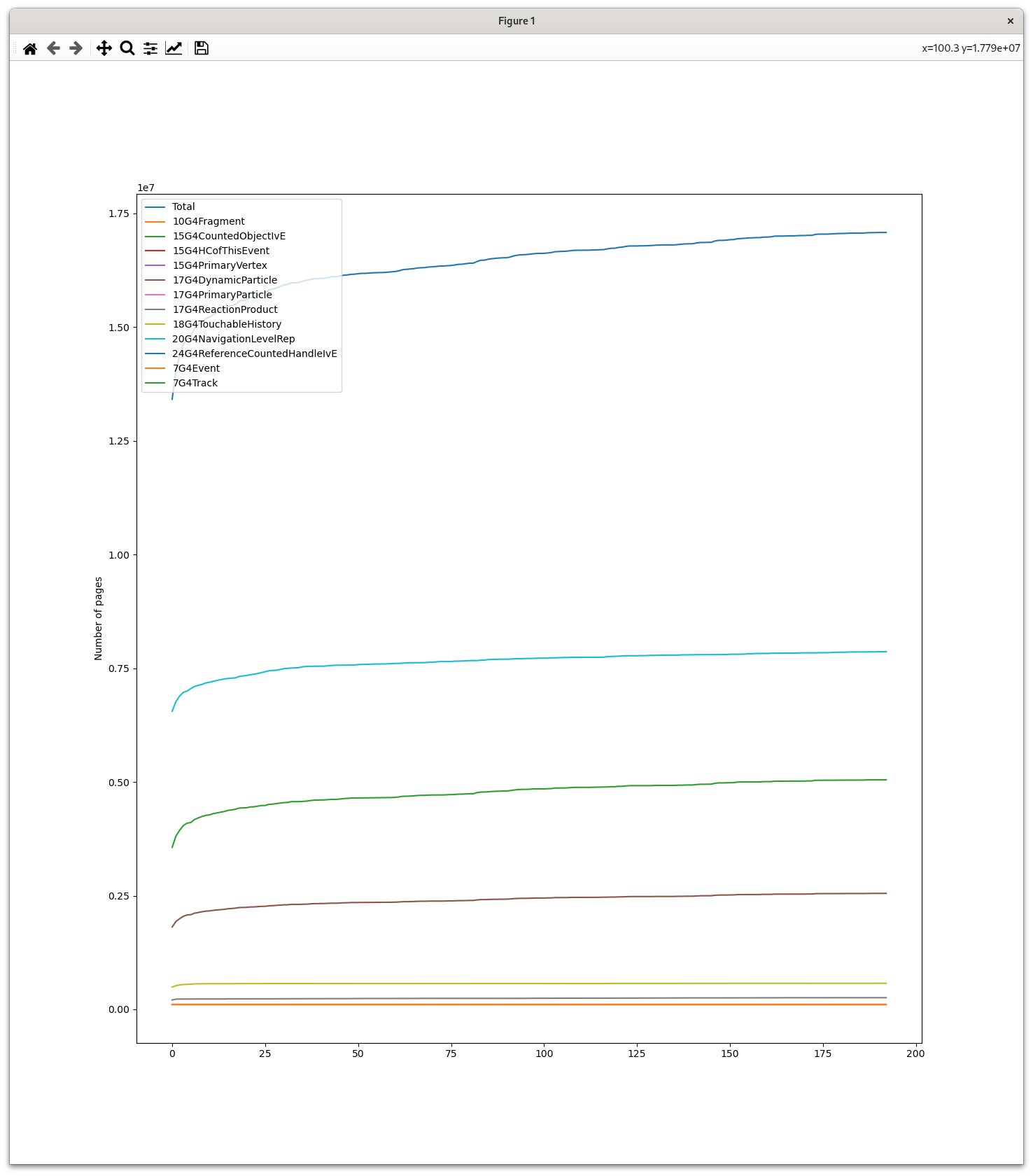
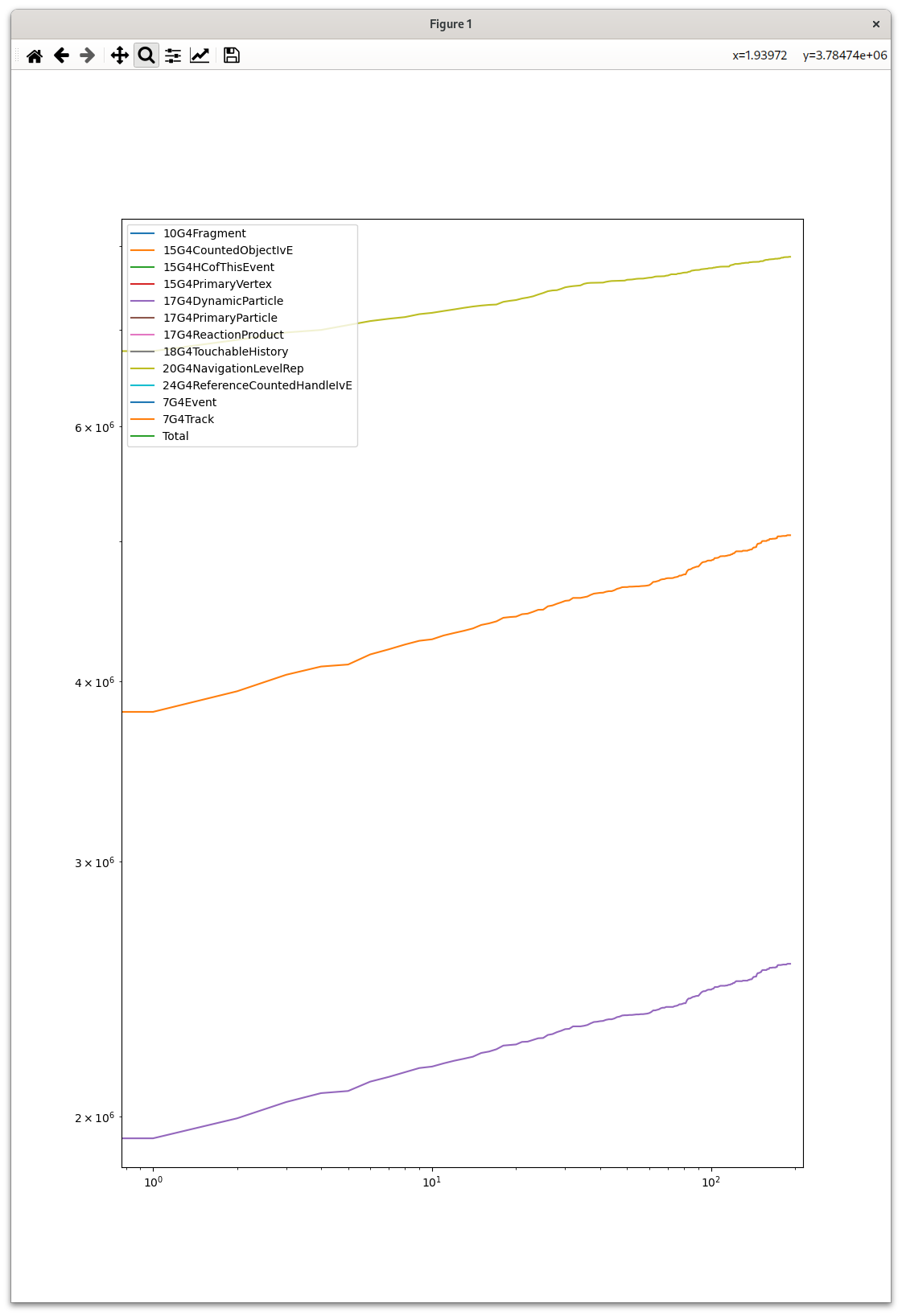
[…] the growth of the allocator pools reaches a plateau after which they become stable
We have not observed that plateau for the largest allocator pools, though, and this is why I was wondering.
[…] you should be aware that resetting their storage will not return you back the memory to the free store, but rather allow you to reuse the allocated space until you’ll reach again the same occupancy.
I think I am not understanding how the pools work :-/
Should the objects be cleaned up manually, then? If they were cleaned up, I would expect the pool size to grow in steps, when there is a new run (or whatever period between clean-up points) where the number of objects requires a larger number of pages than any runs so far. But for those three curves it keeps growing at a quite stable rate.
I am trying to see if I am keeping handles to those objects in my application that would prevent cleanup, but that is not the case. And I would expect much larger memory growth if dynamic particles and tracks were not cleaned up at all… Or maybe not?
As you have experienced, there is not a general recipe on how to manipulate the allocator’s storage, as their contents are used in different stages and states of the simulator, and for some of them manipulation may not be at all possible.
This was my suspicion. I suppose part of the solution will be studying how memory behaves and impose restrictions, plus smoothly restarting the simulation in case of a crash.
Note that you also have the possibility to tune the page size of allocator to faster stabilise its growth, if necessary.
Thanks for the suggestion, we probably want to do that regardless.
The effect of resetting the storage for some allocators can be irrelevant, for others, like the navigation levels, can be a slight degradation of run-time performance.
Thanks! It will anyway have to be tested. I will try to investigate a bit, this would be useful to have in the documentation.